Product
비식별화 솔루션
SDGUARD 개요
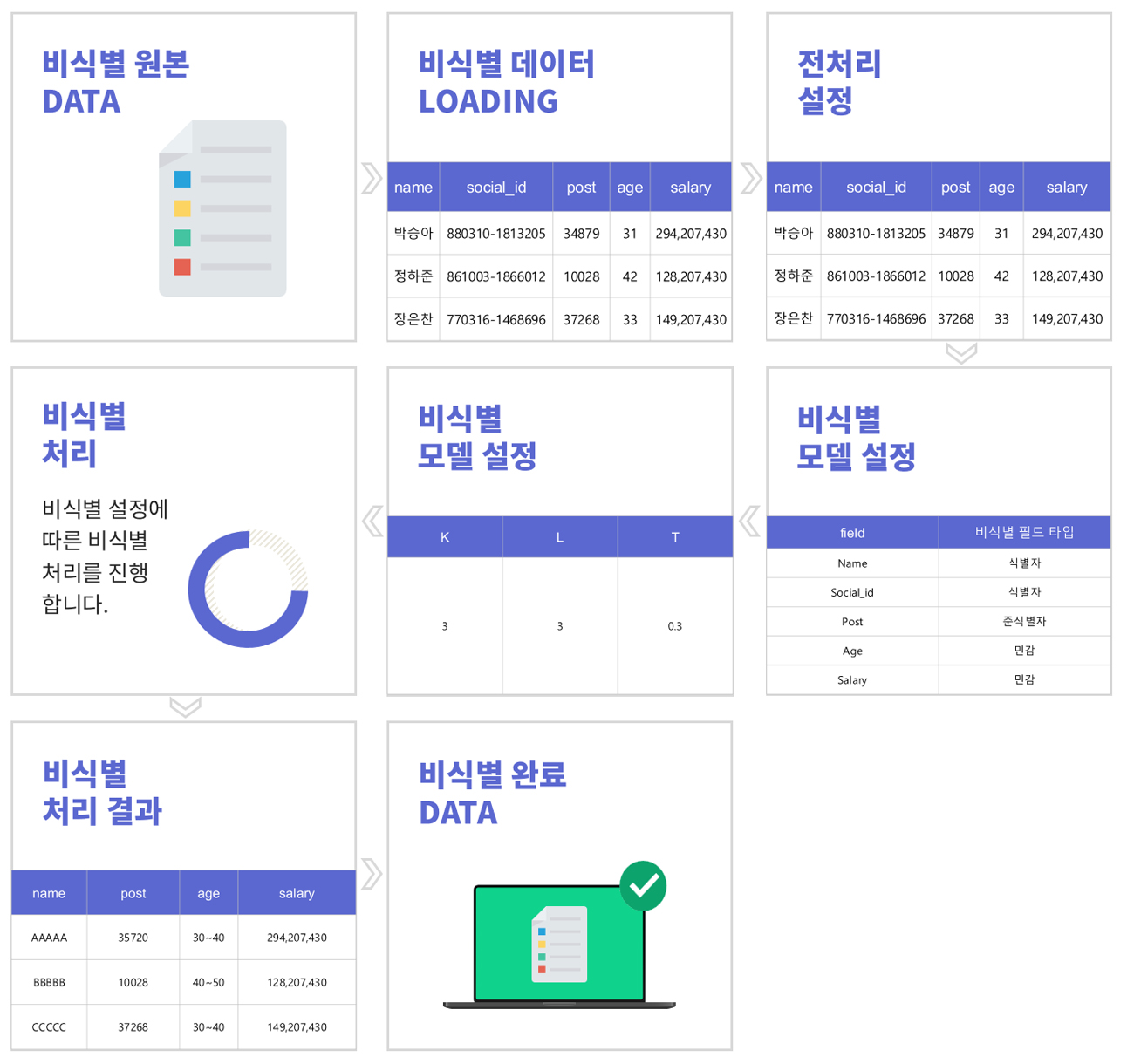
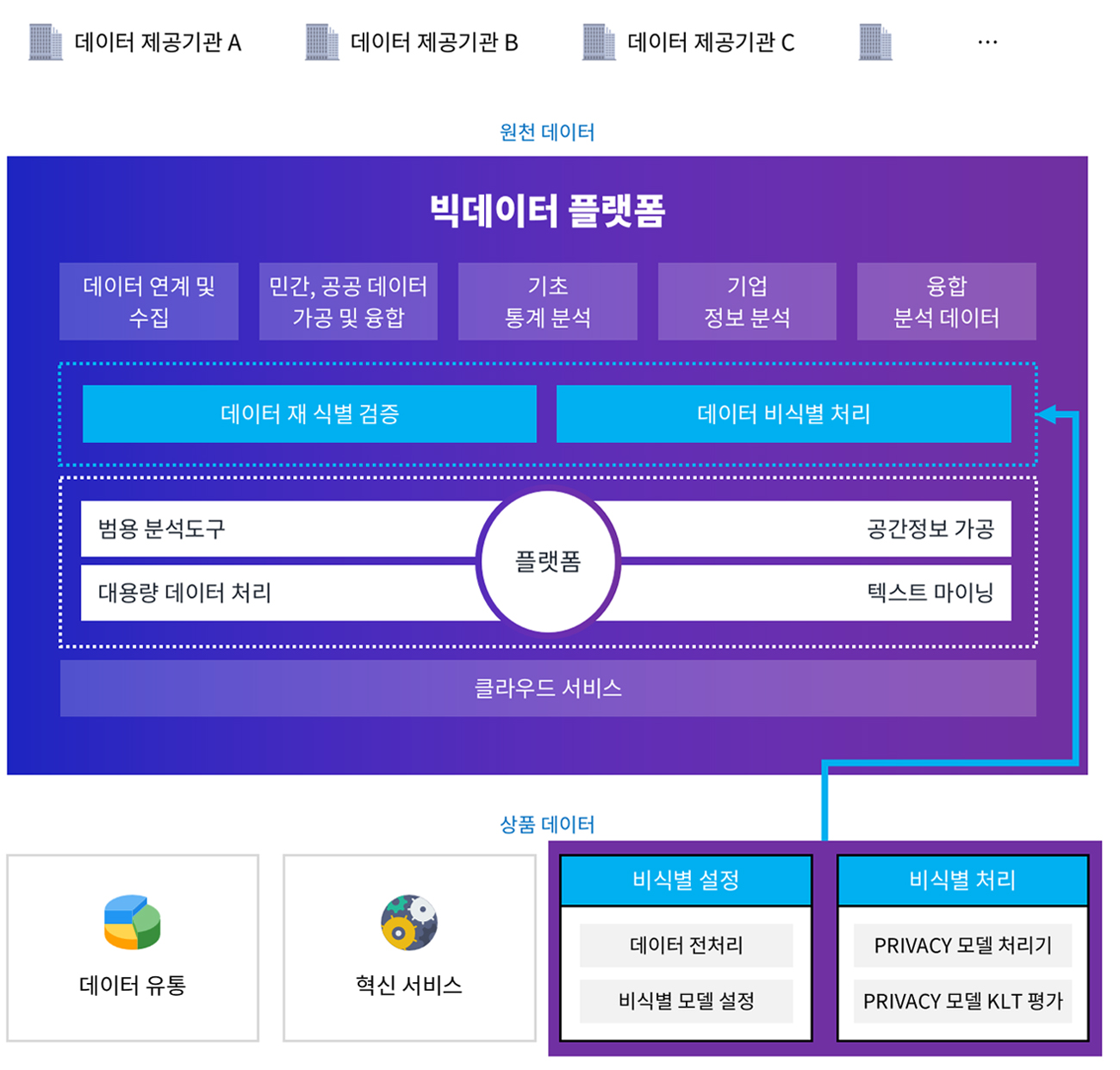
비식별화 솔루션 SDGUARD는 기업에서 보유하고 있는 민감한 개인정보 데이터를 비식별 처리하는 통합 솔루션입니다.
- 17가지 고전적 비식별 처리 방법 제공
- 고전적 비식별 처리 방법으로 가명처리,
총계 처리,데이터 삭제,데이터 범주화,
데이터 마스킹의 비식별 처리기법을 제공합니다.
(17개의 세부 처리기술)
- K-익명성, L-다양성, T-근접성 평가방법 제공
- 기본 프라이버시 보호 모델로 K-익명성을 사용하며,
민감정보가 포함된 데이터의 경우 L-다양성 및 T-근접성 모델도 적용할 수 있습니다.
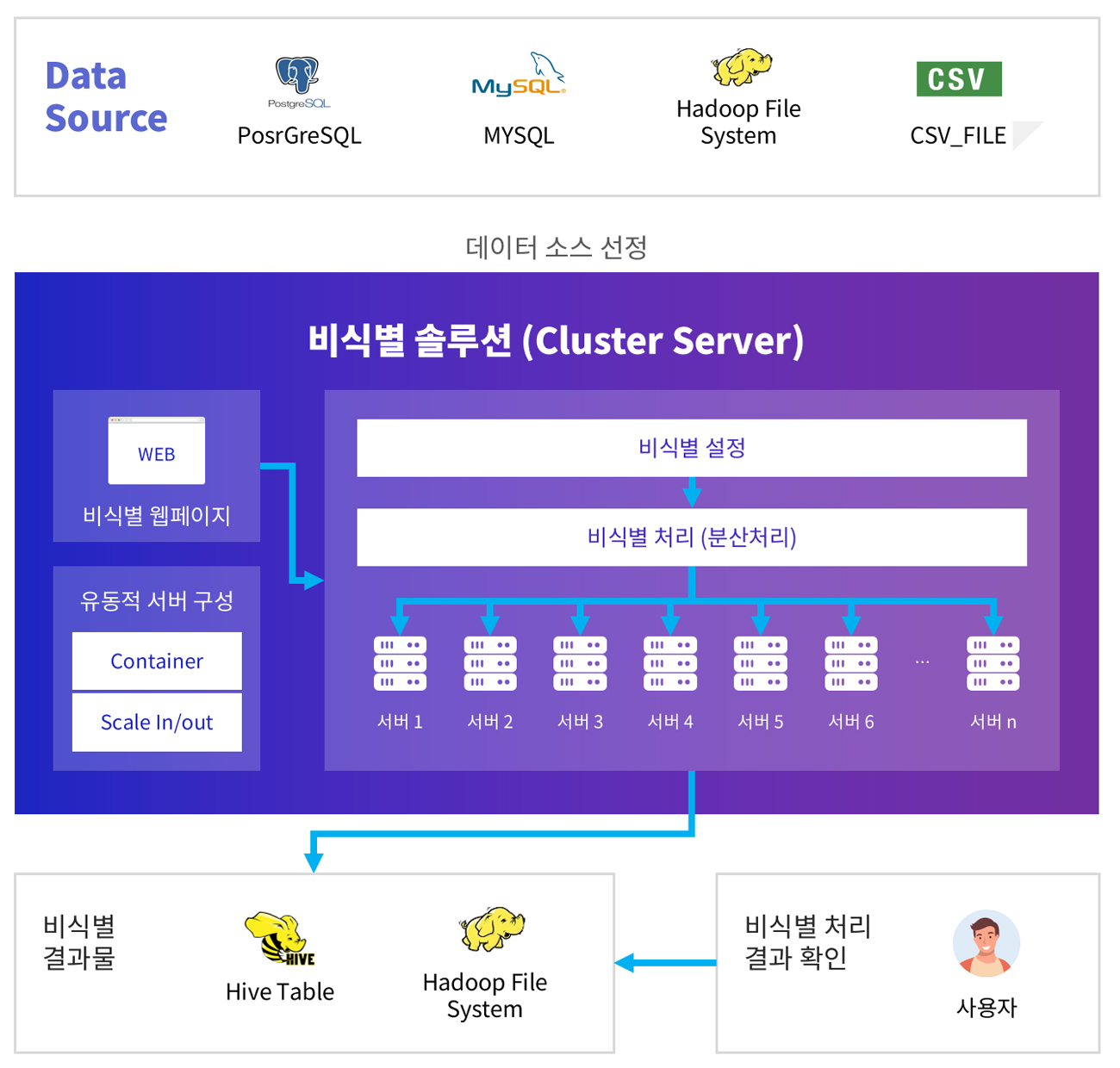
- In-Memory 및 데이터 분산 처리 환경 제공
- 다수의 서버 구성으로 분산처리를 통해
단일 서버 대비 처리속도 향상이 가능합니다.
또한 In-Memory 기반의 처리기술을 적용하여 처리속도를 향상시켰습니다.
- 다양한 데이터 타입 연계
- 일반적인 File형식의 데이터(CSV 등),
관계형데이터베이스 (MySQL, Oracle 등), 빅데이터 데이터베이스(Hive) 연계 지원이 가능합니다.